
robots.txtについて解説します。
robots.txtとは
robots.txtとは検索エンジンのクローラーに対してクロールするページを制御するためのファイルのこと。
Googlebotを含むクローラーは原則的に辿れるすべてのURLをクロールしようとします。
その際にrobots.txtを使用し「どのURLのクロールを許可するか」「どのURLのクロールを拒否するか」と伝え、辿らせたいページと辿らせたくないページを分けることが可能です。
記載できる内容
robots.txtに記載できる内容は次の通りです。
- 対象のユーザーエージェント(User-agent):どの検索エンジンクローラーに対して命令するかを選択できる
- 許可・拒否設定:辿らせたいページ、辿らせたくないページの区分ができる
- sitemapの記述:sitemapの場所を知らせてクローラーに発見してもらうことができる
- コメントアウト:コメントアウト(#)でメモや備忘としての記述も可能
- crawl-delay、noindex、nofollow:クロール頻度の調整やnoindex、nofollowなども調整可能(ただしGoogleはこの機能はサポート外)
robots.txt利用時の注意点
robots.txt利用時の注意点です。
ドメイン・サブドメインのルートディレクトリへ設置する必要がある
robots.txtはドメイン・サブドメインのルートディレクトリへ設置する必要があります。
◯
https://example.com/robots.txt
https://sub.example.com/robots.txt
×
https://example.com/dir/robots.txt
ワイルドカードが使用できる
robots.txtでは2つのワイルドカードを使用可能です。
*(直前の0以上の文字列にマッチするもの)
$(文末がマッチするもの)
これらを組み合わせることでクローラーへのURL指示の幅が広がります。
また設定の際には、誤設定がないように必ずrobots.txtテスターツールを使用しましょう(後述)。
robots.txtで制御してもインデックスされることがある
robots.txtでクローラーを制御しても、他ページからのリンクなどでインデックスをする可能性があります。
その際robots.txtで制御されているため、クローラーはページの内容そのものは読み込めず、検索結果に「このページに関する情報はありません」と表示されます。
タイトルなども読めないため、ページのURLや、そのページに向けられているアンカーテキストなどをそのまま表示することがあります。
noindex化したページをrobots.txtで制御しない
noindexでインデックスさせたくないページをrobots.txtで制御しないようにしましょう。
robots.txtで制御すると、クローラーがnoindexを設置しているページを読み込むことができません。
robots.txtが5xxエラーを返すケース
robots.txtが5xxエラーを返す場合、少し特殊な挙動となる点に注意しましょう。
5xxエラーを返した場合、Google側では「サイトにクロールが許可されていない」と判断するため、サイトがGoogleの検索結果から消えてしまう可能性があります。
30日経過しても状況が改善されない場合、最後のキャッシュコピーを使用しクロールを再開します。
(robots.txtのキャッシュコピーがない場合にはすべてのURLをクロール)
robots.txtテスターツール
robots.txtにURL制御などの設定をするような場合、事前に必ずrobots.txtテスターツールを使用し、誤設定がないかを確認するようにしましょう。
robots.txtはクローラーに対しての命令のため非常に強力です。
誤った設定でクロール拒否をしてしまうと意図しないページのクロールが止まってしまう可能性があります。
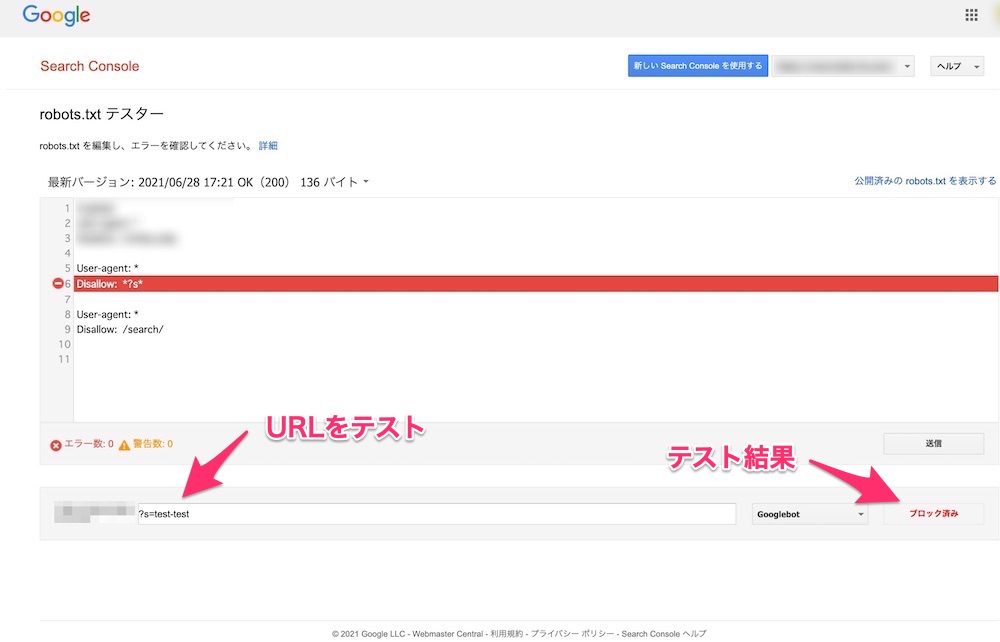
(URLテストの様子。設定を変更した場合Googleがrobots.txtをどのように読むかが事前に必ず確認する)
robots.txtを更新した際の対処
robots.txtを更新した際に、Googleは24時間以内に更新を検知しますので基本的には特別な対処は不要です。
ただし、より早く検知してもらいたい場合にはrobots.txtテスターで送信機能があるのでそちらを利用しましょう。
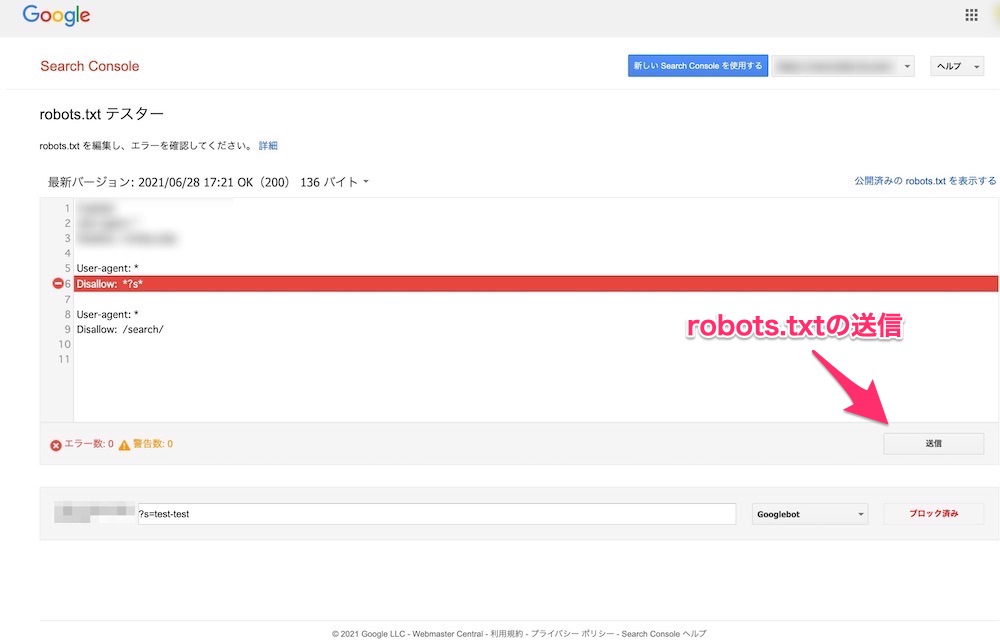
robots.txtテスター右下に「送信」ボタンがあるので押し、Googleに検知を促します。
